

前言
此前写过一些有关预测技术的文章,然而对于从事需求计划预测工作的人员而言,依旧存在诸多疑问。即便掌握了相应的预测技术与模型,他们在实际操作中仍不知该如何运用。例如,什么时候适合采用移动平均法,什么时候又该运用指数平滑法呢?实际上,选用合适的预测技术或者预测模型,应当依据数据的形态以及其所蕴含的规律来确定。这就要求我们必须先深入了解自身数据具备哪些规律和特点,这些规律和特点呈现出何种形态,进而依据这些特征去寻找适配的模型和预测技术。
为预测数据挑选恰当的预测模型和方法,其中一个最为关键的步骤就是考量预测数据的不同形态。数据形态可能是较为明显的,也可能是相对隐蔽的。而判断数据形态最直接的途径就是借助图表图形进行观测。所以,当我们获取到数据时,或许最为重要的事情就是将数据转化为可视化图表。这样做能够帮助我们判别数据的特点和规律,毕竟通过图表能够最轻易地发现数据的基本特征,像基本模式以及异常观测结果等。有时候,图表还能够对数据中的某些变化给出可能的解释。
一、 什么是数据形态(Data Pattern)?
数据形态就是数据所呈现的特征,通过图形描述出的形状。通常一个数据通常包含水平,趋势,季节,周期和噪音或异常值等一个或多个成分,或者多个成分组合起来的,通过图形可以将这些特性描述或展示出来,给我们直观的感受,使我们可以通过图形进行直接的判断出数据的模式。如图:
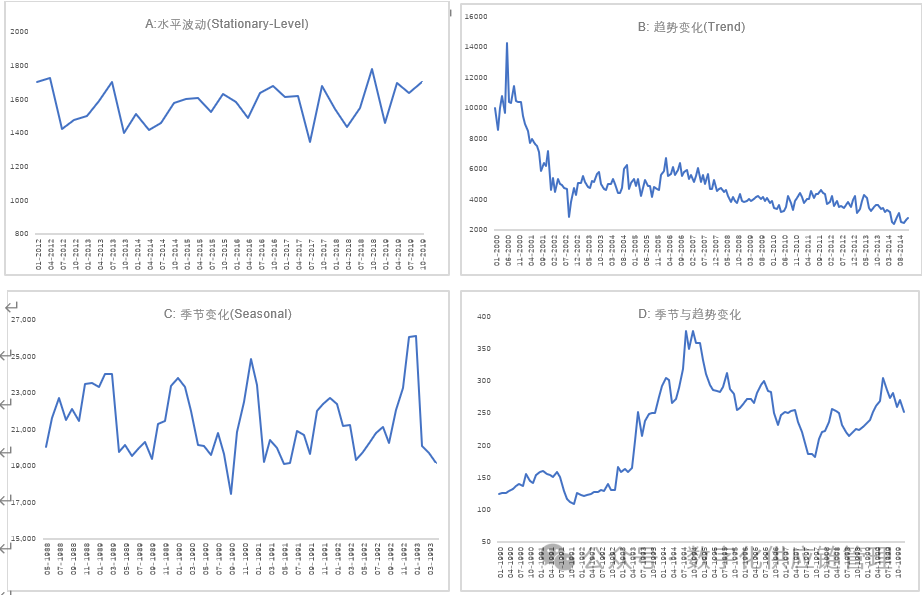
图1A:水平模式;图1B:趋势模式;图1C: 季节模式;图1D:季节趋势(不规则趋势)
二、 水平(Stationary,通常用L (Level)表示):当随着时间的推移所观察的数据围绕恒定水平或均值波动时,就会存在水平模式。
一种产品的销售随时间推移既不增加也不减少的平稳状态就属于这种类型,比如,我们的日常消费品牙膏牙刷等,被视为具有水平模式。 举例说明,下图是某款洗发水的两年的历史销售,虽然销售量在每个月份之间有波动,但是,两年的销量总体是比较平衡的,没有明显的增长或者下降趋势,也明显不存在季节性。而这些波动,我们可以认为是随机干扰因素,我们可以通过移动平均或者指数平滑把它们平滑掉。
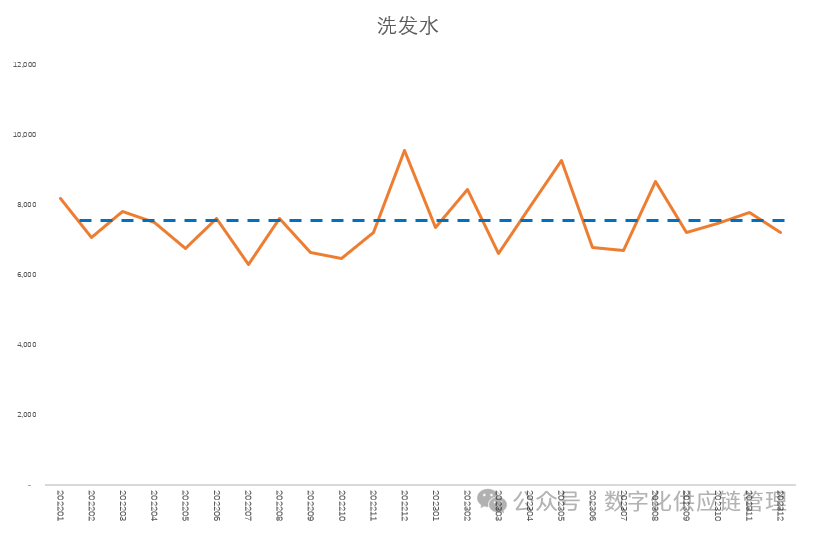
图2:某洗发水两年的历史销售量
对于这样的水平数据形态,合适的预测模型就是移动平均或者简单指数平滑了,通过平滑,将随机干扰因素去除掉,呈现平稳的数据模式。
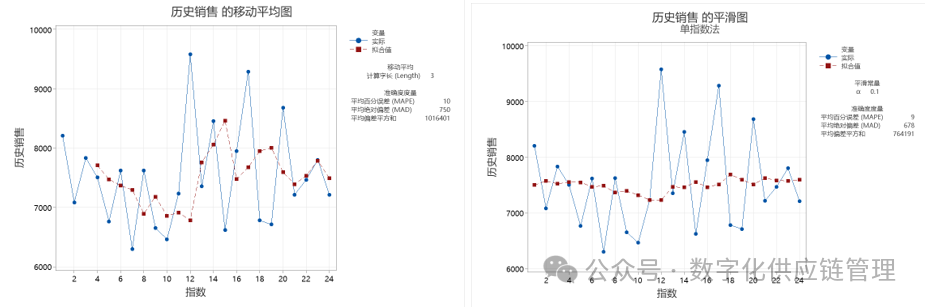
图3:洗发水的移动平均与指数平滑Minitab上的预测结果
三、 趋势(Trend):趋势是代表时间序列在较长一段时间内的增长或下降的形态。
许多宏观经济变量,如美国国民生产总值 (GNP)、就业和工业生产等都表现出趋势行为。比如下图,道琼斯指数2024年的日收盘价格,从年初的37,000多点到年末收盘42,000多点,虽然有短期波动,但是属于长期增长的形态。
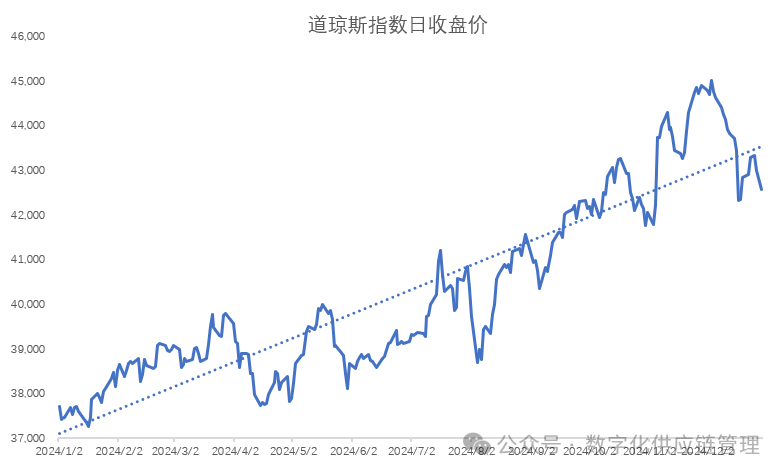
图4:道琼斯指数日收盘价 但很多时候,数据的增长,并不是属于稳定的增长的形态,中间可能会有大的涨跌的情况,并不如像道琼斯指数这样长期稳定的增长。比如下图近5年的中国劳动力成本数据:
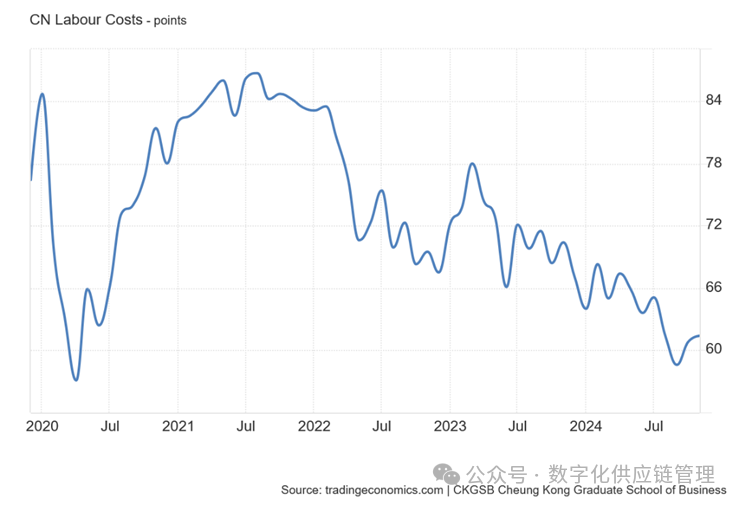
图5:中国劳动成本2020-2024,数据来源: 来源: CKGSB Cheung Kong Graduate School of Business 趋势形态的数据模式,可以用霍尔特(Holt)或布朗线性等趋势指数平滑模型进行预测,或通过二次移动平均或多次移动平均方法,如果数据是比较线性增长的模式,也可以通过一元线性回归分析进行预测。如果是非线性趋势,需要考虑其他更复杂的预测技术与模型,如增长曲线法;指数模型;ARIMA(Box-Jenkins)等方法。
四、周期 (Cyclical):当数据表现出上升和下降的周期性波动,且这些波动不是固定周期时,就存在周期性(C)模式。
周期性成分是围绕趋势的波浪状波动,通常受到总体经济状况的影响。诸如汽车、钢铁和大型家用电器的销售等产品都会表现出这种类型的模式。周期性成分(如果存在)通常会在几年内完成一个周期。周期性波动通常受到经济扩张和收缩(通常称为经济周期)变化的影响。如下图我国的载货汽车生产量,就呈现一定的经济周期。
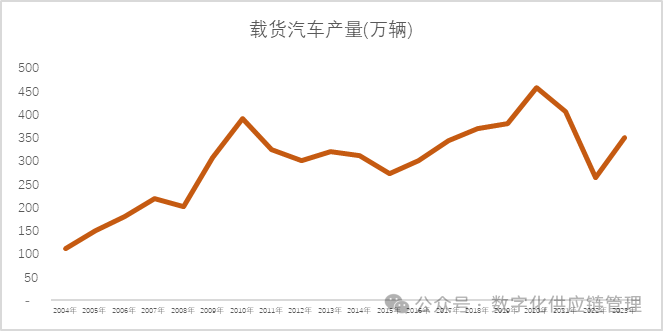
图6:中国载货汽车生产量2004-2023 数据来源:国家统计局国家数据网
我们可以看到2008年金融危机作为一 个周期的起点,到2022年跌入下一个相对的低谷。当然我们可以把从2008到2015年,和从2015到2022年看作为两个周期。
可能20年的周期还不够长,我们再来看一下,美国从1976年到2024年的汽车销售总量:
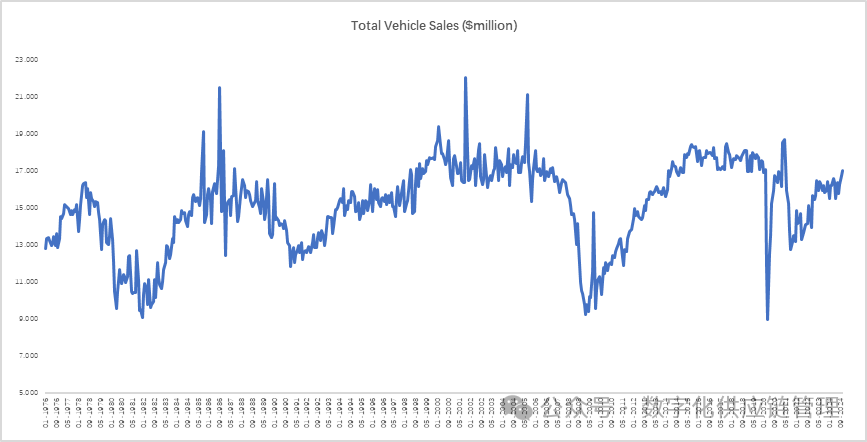
图7:美国从1976年到2024年的月汽车销售总量,数据来源: FRED网站(圣路易斯联邦储备银行)
从图表上我们可以看到1980到1990一个周期,1991到2008一个经济周期,2009到2021年一个经济周期,我们都知道2008年美国次货危机引起的全球的金融危机,而虽然2020年1 月暴发的新冠疫情,但似乎只是短期影响,直到2021年9月才真正进入低俗。
季节性和周期性模式的主要区别在于,前者具有恒定的长度并且定期重复出现,而后者在长度上会有所变化。此外,周期的平均长度通常比季节性的平均长度要长,而且周期的幅度也通常更加多变。
周期成分一般跟随经济周期,而经济周期却不如季节性那么有固定的时间规律容易捕捉,所以要预测周期性的成分并不容易,周期成分可以通过移动平均法将之分离出来,经典分解法、X-12等统计方法产生的目的就是捕捉长期的经济周期规律,但是效果不如预测专家们所预期的那样,因为影响经济周期的因素是非常难以预见到的,偶然的因素太多。
五. 季节(Seasonal):当一系列数据受到季节性因素的影响(例如,一年中的季度、月份或星期几)时,就存在季节性(S)模式。
与我们生活中相关的大多数产品都存在季节性,比如饮料,服装、与季节密切相关的农产品等,与我们的节假日相关的产品,每年春节相关的礼品和家庭用品等,相关客运方面的服务与产品等。比如下图某品牌男士背心的销售,就存在着明显的季节性,每年5月份(考虑到经销商的提前进货期)达到最大的销售量,而在年初1、2月份达到最低点。
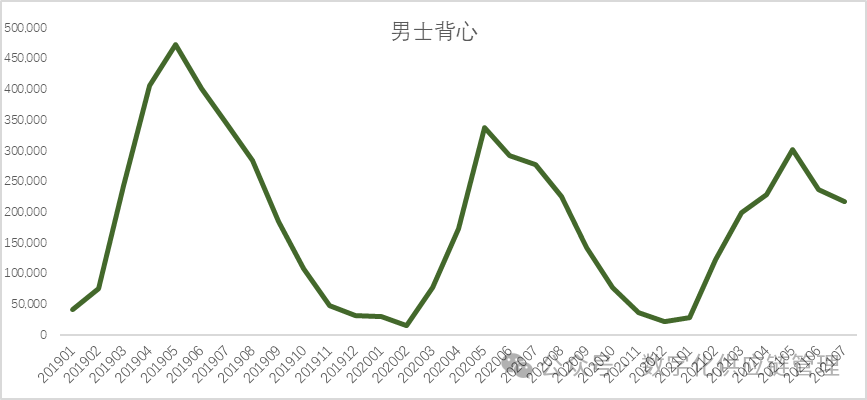
图8:某男士背心两年半的销售
因为我们大多数的产品都具有季节性模式,所以季节性的预测技术是我们必须要掌握的。具有季节性的数据通常可以使用分解法、Winters(季节趋势)指数平滑法、 X-12普查法、 ARIMA 模型(BOX-JENKINS博克斯一詹金斯法)等模型与方法进行预测。如果季节性不存在明显的趋势的情况,则可以使用简单季节模型,只要将季节指数分解出来就可以了。
六、大多数时间序列数据,包含多个成分,是趋势,季节,周期和噪音等几个成分的组合。
下图显示了趋势、季节性和周期性的特点。这样的时间序列数据使预测是序列数据中常见的各种模式。最常用的方法是将模式中存在的季节S、趋势T、周期C和噪音I各个成分分离出来,把噪音去除掉,再把必要的成分组合起来,如把季节和趋势组合起来成为预测模型,则常用的方法之一如经典分解法就是非常好的,也比较容易掌握的方法等。
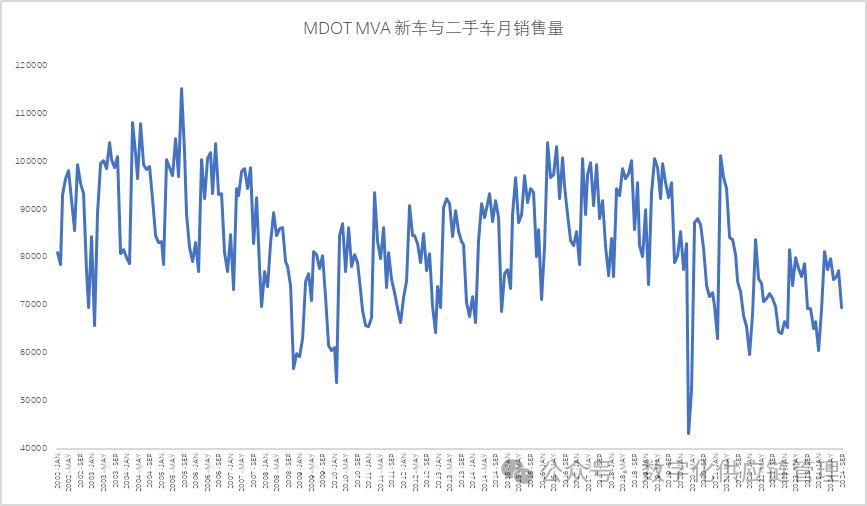
图9:MDOT MVA(马里兰州机动车管理局) 新车与二手车月销售量
但其实很多数据更加复杂,长期来看,序列数据是不平稳的,在趋势有不断的涨跌,还包含季节性特征和一些异常值等,使我们不容易直接从图形上找到其中的模式,如下图:
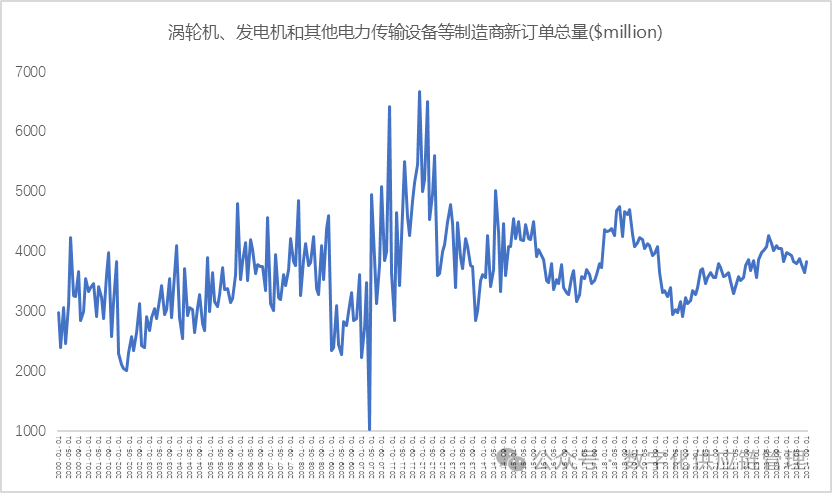
图10:涡轮机、发电机和其他电力传输设备等制造商新订单总量($Million) 数据来源: FRED网站(圣路易斯联邦储备银行)
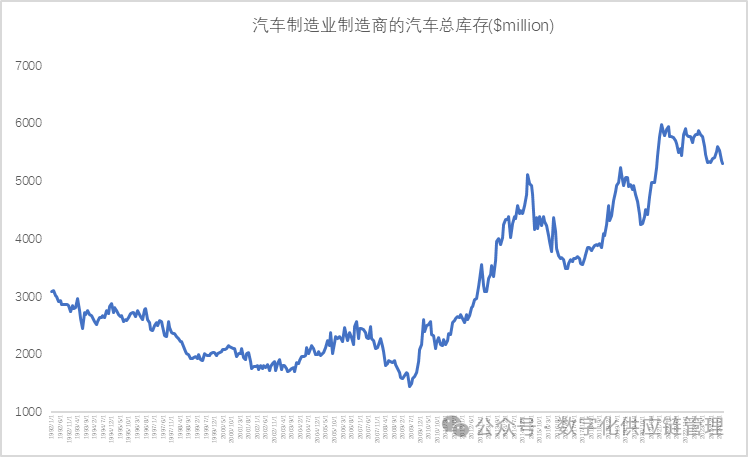
图11:汽车制造业制造商的汽车总库存($million) 数据来源: FRED网站(圣路易斯联邦储备银行)
图10从长期看,虽然没有明显的涨跌,但是长期内的波动却非常的大,似乎还隐含着一定的季节性,而图11就存在非常明显的涨跌,且极具不规律,同时似乎也隐含着季节性。 这样的时间序列数据模式,有时我们很难直接从图形上进行判断得出规律,需要通过其他的方法来帮助我们做更准确的判断。对于时间序列的判断,我需要引入另一个概念,就是ACF, Autocorrelation的缩写,中文叫自相关函数。那么ACF是什么含义呢?简单的说,由于我们的时间序列存在着某种模式,所以每个数据之间是相关的,存在某种相关关系,通过该时间序列数据的滞后阶数与前一序列的比例关系判断序列的相关程度,通常用rk表示,所以它也叫序列相关。关于自相关函数ACF,已经涉及到一些基础的统计专业知识了,由于篇幅的关系,将在下一篇中专门介绍。
注:本文中本人采用了很多的美国的一些行业的统计数据,数据来自美国政府的一些官方网站,这么做的原因不是本人崇洋媚外,而是我们国家和政府机构的官方数据相对有限和不够完善,无法取到我想要的数据,另外很多的行业专业数据都不是免费的,而是收费昂贵,希望未来我们的国家和政府也可以将这方面的统计信息完善和规范起来,并能给广大老百姓提供相关免费的行业和专业的数据。
